In this thesis I explored how to train neural networks more efficiently.
More specifically, the idea was to compress gradient signals during backpropagation using a sparsifying quantization scheme.
The induced sparsity can then be exploited to reduce the computational cost of the matrix multiplications in the training algorithm.
In particular, dithered uniform quantization was chosen.
A stochastic quantization scheme with similar noise properties to SGD, i.e. the quantization noise is unbiased and has controllable variance.
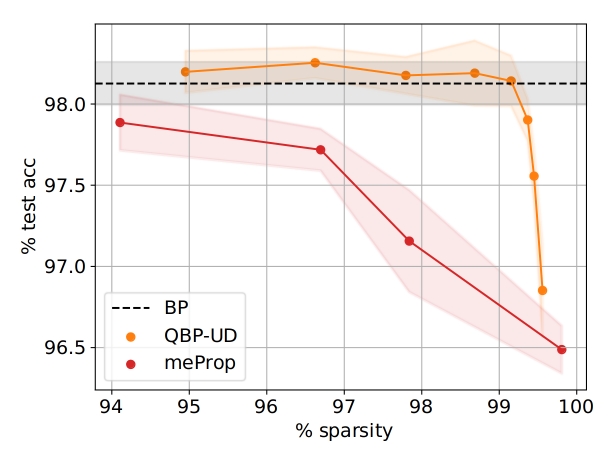
It was shown that this method can achieve 99% sparsity in the relevant gradient matrices when training a fully-connected network on the MNIST image classification dataset while retaining the same generalization performance.
Doing so, it clearly outperforms related approaches with deterministic quantization schemes (see figure below).
This work was done at Fraunhofer HHI.